|
This software is available for non-commercial use only. It
must not be modified or distributed without a written permission of the
author. This software comes without any warranty; use it at your own risk.
If you do use it in your scientific work, please cite the appropriate
publication(s), and include a pointer to this website.
The binaries of ADIOS-Lite
(A demo version which limits the number of extracted patterns to 100)
are available after a short registration.
The algorithm section contains the following:
To install ADIOS, you need to download adios-1.xx-linux.zip. Create a new
directory
mkdir adios
Move adios-1.xx-linux.zip to this directory and unpack it with
unzip adios-1.00-linux.zip
QUICK START
Run the shell script:
train.sh proj_name ; e.g. ./train.sh TA1
The shell script will first convert the corpus TA1.corpus.txt (which is
provided with the package) into a graph. It will then run the ADIOS algorithm
for few seconds and print the results into a text file:
TA1.results.txt
If for any reason you stopped the algorithm and would like
to resume it, use the following script:
resume.sh proj_name ; e.g. ./resume.sh TA1
The algorithm can generate new sentences according to the rules it has
acquired. Use the following script to start generating sentences:
generate.sh proj_name; e.g. ./generate.sh TA1
The newly generated sentences will be found in the file
TA1.generate.txt
The TA1 corpus,
was generated by an
external CFG grammar. Two measures are used to assess the performance of
ADIOS as an unsupervised learner:
Recall and Precision (for
further details see below).
The following shell runs a Recall/Precision test which measure the learning
performance of ADIOS when applied on the TA1 context free grammar.
teacher-learner.sh proj_name ; e.g. ./teacher-learner.sh
TA1
if everything
works properly after 1 minute approximately, the system will report the
following:
results: TA1
Recall = Accepted: 472 out of 500 (0.944)
Precision = Accepted: 404 out of 500 (0.808)
which means that
in this particular run, ADIOS achieved 94% recall and 80% precision. Pay
attention that since the algorithm generates a new corpus for each run the
numbers might be a bit different.
ADIOS USAGE
The main tasks that the ADIOS program can
execute are:
- be trained on a given graph (see Learning Arguments)
- be tested given a new unseen corpus (see Testing Arguments)
- print and visualize the acquired patterns (see Printing Arguments)
- generate new sentences using the acquired patterns (see
Generating Arguments)
The program is invoked as follows:
adios.exe [-options] -o project_name
Example:
./adios.exe -a train -i TA1.idx -g TA1.grp
-E 0.8 -S 0.01 -o TA1
Learning Arguments:
-a command ->
select between training (train) testing (test)
printing results (print) generating sentences
(generate)
-o output_file -> file to store output results
(default: out.txt)
-i index_file -> the indices file
-g graph_file ->
the graph file ; when the -g option is
omitted
the algorithm tries to resume into its last
stored sate.
-E [0..1] -> the ETA
parameter (Default: 0.8)
-S [0..1] -> the
patterns p-value (Default: 0.01)
-C [0..1] -> the
minimal coverage required from a formed
Equivalence Class (Default: 0.65)
-W [3,4,5...] -> the context window size
(Default: 5)
when -W is set to 1000, the algorithm runs
in MEX mode.
-r [0,1,2,3] -> select between the rewiring
modes: 0 none;
1 single; 2 multiple; 3 batch
-A [1..] -> The
largest pattern size: All patterns with
size larger than A will be treated as equal
in the rewiring process.
-B {1..] -> The
minimum pattern size
output files:
proj_name.trace.log: summary of the algorithm
progress
proj_name.results.txt: list of the acquired patterns
and properties
Testing Arguments:
-R int
-> the parser max recursions (Default R=10)
-I test_file -> file with the
testing data
output files:
proj_name.test.results.txt: For each input sentence the file provides a list of
patterns and paths that span the sentence or parts of it.
proj_name.test.summary.txt: For each input
sentence a list of patterns (IDs) that span the
sentence or parts of it.
proj_name.test.classify.txt: Classification of
the novel sentence to acceptable and
non-acceptable according to the acquired
grammar.
Generating Arguments:
-n int
-> generate n novel sentences into the output file
-R int -> the generator max recursions
(Default R=10)
output files:
proj_name.generate.txt: The corpus containing the
new novel senetnces generated by ADIOS
proj_name.generate.log: A log file which describes
the generate process.
Learning Additional Arguments:
-s int
-> start the training from the s search-path
-n int -> process only the first n
sentences in the
corpus
-c int
-> if no patterns are found in the next c
iterations stop (Default: 200)
-v [0,1] -> verbosity level, 1 - on 0 - off
(Default 0) A
ADDITIONAL TOOLS
CREATE_GRAPH USAGE
creates the ADIOS graph to be used by the
adios.exe. The ADIOS graph is consisted of an
index file project_name.idx and a graph file
project_name.grp
./create_graph.exe -f corpus_file -o project_name
-f corpus_file -> the
file name of corpus
-o project_name -> the name of the project.
Example:
./create_graph.exe -f TA1.txt -o TA1
SCRAMBLER USAGE
creates a new random order permutations of the corpus sentences.
./scrambler.exe
-f corpus_file -> the file name of corpus
-o output_file -> the output file.
CONVERT GRAMMAR USAGE
convert an external CFG into the ADIOS files
./convert_grammar.exe
-l lexcion_file -> the lexicon file name
-g grammar_file -> the grammar file name
-o proj_name -> the name of
the project
PREPROCESSING:
The aim of the preprocessing stage is to convert a corpus into a
format that is compatible with the ADIOS algorithm. The program loads a corpus
file (e.g., corpus.txt) and converts it into two files: an index file and a
graph file. In what follows, the TA1 corpus (included in the ADIOS package)
serves as a running example:
* Jim and Cindy have a winning personality #
* Beth won't be released until Friday #
* a horse barked #
* the dog loved a cat #
* the cats are living very far away #
Each sentence must start on a new line, and each primitive string
(e.g., a single word) must be delimited by spaces. The '*' and the '#' symbols
(meaning BEGIN and END of a sentence, respectively) must be used.
The following command:
./create_graph.exe -f TA1.txt -o TA1
creates two files: an index file
(TA1.idx), which is a text file containing all the lexicon entries; and a graph
file (TA1.grp), which is a text file describing the structure of the ADIOS
graph.
LEARNING:
At the end of the preprocessing stage, ADIOS is ready to start
learning. You can initiate the process as follows:
./adios.exe -a train -i TA1.idx -g TA1.grp -E
0.8 -S 0.01 -o TA1
During learning, the state of the algorithm is saved periodically
into three different binary files:
patterns.dat, graph.dat, and sysparams.dat. These binary files, together with the
index file (e.g., TA1.idx), contain all the information necessary to restore the
system's learning state, as well as test it, print the patterns, or generate
sentences using the current grammar. Thus, at any time, you can halt the program
and then restore it, as follows:
./adios.exe -a train -i TA1.idx
In this usage, when the graph file is not provided in the command line, the
algorithm tries to use the existing (saved) binary files (graph.dat,
patterns.dat and sysparams.dat), instead of starting a new session.
During learning, the algorithm updates the proj_name.trace file
with its learning state. The file contains the following information: Number of
iterations, Number of patterns that have been found, Number of Equivalence
classes, number of edges in the graph, the entropy rate (bits), the size of the
graph, and its patterns, and the compression rate.
An Example of a proj_name.trace.log file:
###################################################################
ADIOS V1.00 (Automatic DIstilation Of Strctures)
Thu Mar 17 19:38:29 2005
Verbosity level: 0
Context window-length: 5
Coverage: 0.65
Eta: 0.5
P-value: 0.99
Rewiring mode: Single
itrs = number of iterations
#ptrs = number of patterns
#ecs = number of equiavlence classes
#edges = number of edges
entropy = entropy (bits)
size = size (bits)
comp = compression (%)
itrs #ptrs #ecs #edges entropy size
comp
0 0 0
2852 1.1462 44256 100
100 27 14
957 0.545923 16640 37.5994
200 30 15
924 0.542127 16336 36.9125
300 31 16
916 0.542689 16320 36.8764
400 32 17
909 0.545649 16304 36.8402
###################################################################
At the end of the learning process, the algorithm provide a file with
details about the learning session, the patterns
it has found and a spectra analysis.
an example of the
proj_name.results.txt
###################################################################
ADIOS V1.00 (Automatic DIstilation
Of Strctures)
Thu Mar 17 19:38:29 2005
Verbosity level: 0
Context window-length: 5
Coverage: 0.65
Eta: 0.8
P-value: 0.9
Rewiring mode: Single
Number of patterns: 36
Number of equivalence classes: 36
Initial Size: 14576 (bits)
Total size after learning: 14576 (bits)
Compression: 100%
Table of extracted patterns:
ID: unique id
seq: sequence
p-value: significance
gen: generalization factor [1..0]
len: length
occ: occurrences in corpus
ID seq
p-value gen len occ
P44 (the,E45)
0 1
2 157
E45 {bird,cat,cow,dog,horse,rabbit}
P46 (that,E47,thinks,that) 4.1e-07 1
4 127
E47 {Beth,Cindy,George,Jim,Joe,Pam}
P48 (E47,believes,E49)
0 0.5
4.1 153
E49 {that,P46}
P50 (that,P44,is,E51,to)
3.6e-05 0.8 6 32
E51 {eager,easy,tough}
P52 (E53,E54,that,P48)
0 0.06 7.1
49
E53 {Beth,Cindy,Jim,Joe,Pam}
E54 {believe,think,thinks}
P55 (E47,E54,P46)
1.1e-07 0.18 6 39
P56 (to,E57,is)
0 1
3 93
E57 {please,read}
P58 (that,E59,is,E51,to,E57) 4.7e-07 0.36 6
12
...
Pattern Spectra:
histogram of pattern types, whose bins are
labeled by sequences such as (T,P) or (E,E,T) E
standing for equivalence class, T for
tree-terminal (original unit) and P for Pattern.
(T,T) 0
(T,E) 0.027777778
(T,P) 0
(E,T) 0
(E,E) 0
(E,P) 0.083333333
(P,T) 0
(P,E) 0.027777778
(P,P) 0.27777778
(T,T,T) 0.055555556
(T,T,E) 0
(T,T,P) 0.027777778
(T,E,T) 0.027777778
(T,E,E) 0
(T,E,P) 0
###################################################################
GENERATING NEW SENTENCES
The '-a generate' option generates new
sentences using the acquired patterns. The -n option determines their number.
The following command creates 1000 novel sentnces.
./adios.exe -a generate -i TA1.idx -n 1000
The sentences can be found in the TA1.generate.txt file.
###################################################################
* that the rabbit is easy to please worries
Jim
#
* Jim believes that George thinks that to please
is easy #
* Beth think that Cindy believes that Joe thinks
that to read is easy #
* that the rabbit is easy to please bothers the
cat #
* Jim thinks that Beth believes that Cindy
thinks that the rabbit barks and t
he cat jumps , doesn't she ? #
* Beth thinks that Joe thinks that Pam thinks
that to read is tough #
* Jim believe that Pam thinks that to please is
tough #
* that Joe is eager to read worries Cindy #
* Joe believes that Joe thinks that to read is
tough #
* that Joe is easy to please annoys the horse #
* Cindy believes that Jim thinks that Pam thinks
that to please is easy #
* Jim believes that Jim thinks that George
believes that Cindy thinks that to
read is easy #
* that the bird is tough to please disturbs the
bird #
###################################################################
The generate
option creates a log file, TA1.generate.log, which shows the order of the DFS
search that has produced the sentences. Each sentence starts on a new line, and
contains in parentheses the list (ID,
lexicon_entry; depth), which records the order of the search. In
that list, ID is the unique ID number of the terminal or the pattern,
lexicon_entry is the terminal string (for patterns the label is empty);
depth is the current depth of the search.
###################################################################
(2 : *;0) (63 : ;0) (50 : ;1) (36
:
that;2) (44 : ;2) (37 : the;3) (45 :;3) (33 :
rabbit;4) (28 : is;2) (51 : ;2) (25 :
easy;3) (41 : to;2) (57 :;1) (32 :
please;2) (64 : ;1) (43 :
worries;2) (8 : Jim;0)
(2 : *;0) (60 : ;0) (48 : ;1) (47 : ;2) (8 :
Jim;3) (15 : believes;2) (49: ;2) (46 : ;3) (36
: that;4) (47 : ;4) (7 : George;5) (40 :
thinks;4) (36 : that;4) (56 : ;1) (41 : to;2)
(57 : ;2) (32 : please;3) (28 : is;2) (25 :
easy;0)
(2 : *;0) (72 : ;0) (52 : ;1) (53 : ;2) (5 :
Beth;3) (54 : ;2) (39 : think;3) (36 : that;2)
(48 : ;2) (47 : ;3) (6 : Cindy;4) (15 :
believes;3) (49: ;3) (46 : ;4) (36 : that;5) (47
: ;5) (9 : Joe;6) (40 : thinks;5) (36 :that;5)
(56 : ;1) (41 : to;2) (57 : ;2) (34 : read;3)
(28 : is;2) (25 : easy;0)
###################################################################
IMPORTING EXTERNAL GRAMMAR
Any external CFG grammar (which may include
loops) can be converted into the ADIOS representation of graph and patterns.
This feature can be used to test the precision of the learning of an artificial
CFG grammar. The format of the external CFG grammar is described
here. The
utility convert_grammar.exe requires two files as input: (1) a lexicon file, and
(2) a grammar file. The following command converts the grammar TA1 into ADIOS
graph and patterns (the utility creates graph.dat, pattern.dat and TA1.idx
files).
./convert_grammar.exe -g TA1.cfg -l
TA1.lex -o TA1
If the conversion process is completed without
an error, ADIOS can treat the converted grammar as if it were acquired (e.g.,
use it to print, generate, test, etc.)
TESTING
Two measures are used to assess the performance
of ADIOS as an unsupervised learner of natural language and artificial grammars:
Precision and
Recall. In the artificial-grammar experiments,
which start with a target grammar, a teacher instance of the model is first
pre-loaded with this grammar. We illustrate this by converting the external
Context Free Grammar TA1 into ADIOS representation:
./convert_grammar.exe -g TA1.cfg -l
TA1.lex -o TA1
The resulting instance of ADIOS, also known as
the Teacher, is now used to create the training corpus
(Ctraining):
./adios.exe -a generate -i TA1.idx -R 10 -n
500 -o TA1
This command will generate a corpus of 500
sentences. The generation process may exceed the recursion depth threshold (set
to 10). In such cases, the symbol ~ will appear as part of the sentence,
indicating that it is incomplete. To remove those sentences from the corpus you
can use the following command:
sed /\~/d TA1.generate.txt | head -n 400 >
TA1.Ctraining.txt
The command removes the sentences with the ~
symbol, and stores the first 400 sentences in the TA1.corpus.txt file.
We will now create an additional corpus,
Ctarget, that contains
only novel sentences that do not appear in Ctraining. This corpus will be
used later to test the recall of the learning process. We use the same procedure
as described above to create Ctarget.
It is a good idea to store the
Teacher files including its corpora in a zip file:
zip TA1.teacher.zip graph.dat patterns.dat
TA1.idx TA1.Ctraining.txt TA1.Ctarget.txt
Once the corpus is ready, we can proceed and
create the ADIOS graph, and then train the ADIOS algorithm, as explained in the
PREPROCESSING and LEARNING sections. After training, the learner generates a
test corpus Clearner:
./adios.exe -a generate -i TA1.idx -R 10 -n
500 -o TA1
The Learner files including its corpora
can also be stored in a zip file:
zip TA1.learner.zip graph.dat patterns.dat
TA1.idx TA1.CLearner.txt
These two corpora, Clearner and Ctarget , are used to
calculate precision (the proportion of Clearner sentences accepted
by the Teacher), and recall (the proportion of Ctarget sentences accepted by
the Learner). A sentence is accepted if it precisely fits one of the
paths in the ADIOS graph (that is, it can be generated by the path).To measure
the precision we use the following command
(make sure that the dat files and the index files indeed belong to the
Teacher; one way of doing that is to unzip the file
TA1.teacher.zip
):
./adios.exe -a test -i TA1.idx -I
TA1.CLearner.txt -o TA1
This command calculates the proportion of Clearner sentences accepted
by the Teacher. The results appear in three different files:
TA1.test.results.txt:
For each input sentence the file provides a list of patterns and paths that span
the sentence or parts of it.
###################################################################
INPUT: 3 BEGIN [2 ; * ] [6 ; Cindy ] [40 ;
thinks ] [36 ; that ] [9 ; Joe ] [40; thinks ]
[36 ; that ] [41 ; to ] [32 ; please ] [28 ; is
] [42 ; tough ]
PATTERN: 48
E47 : (1, 1) 1;
E49 : (2, 2) 1; (5, 5) 1;
that : (3, 3) 1; (6, 6) 1;
AFFINITY:
SPAN = (1, 3) WEIGHT = 1 : Cindy thinks that
PATTERN: 52
E53 : (2, 2) 1; (5, 5) 1;
that : (3, 3) 1; (6, 6) 1;
AFFINITY:
SPAN = (2, 3) WEIGHT = 1 : thinks that
SPAN = (5, 6) WEIGHT = 1 : thinks that
PATTERN: 54
to : (7, 7) 1;
E55 : (8, 8) 1;
is : (9, 9) 1;
AFFINITY:
SPAN = (7, 9) WEIGHT = 1 : to please is
PATTERN: 66
E67 : (4, 4) 1;
P52 : (2, 3) 1; (5, 6) 1;
AFFINITY:
SPAN = (4, 6) WEIGHT = 1 : Joe thinks that
PATTERN: 70
P48 : (1, 3) 1;
E71 : (4, 6) 1;
AFFINITY:
SPAN = (1, 6) WEIGHT = 1 : Cindy thinks that Joe
thinks that
PATTERN: 72
P70 : (1, 6) 1;
P54 : (7, 9) 1;
AFFINITY:
SPAN = (1, 9) WEIGHT = 1 : Cindy thinks that Joe
thinks that to please is
Full span by path: 72 42
Accepted * Cindy thinks that Joe thinks that to
please is tough #
###################################################################
TA1.test.summary.txt:
For each input
sentence a list patterns (IDs) that span the sentence or parts of it.
###################################################################
192 [ 46 52 52 54 66 68 80 ]
Accepted
193 [ 46 46 52 52 54 61 68 80 ] Accepted
194 [ 46 48 52 52 54 64 70 72 ] Accepted
195 [ 48 48 52 52 54 79 84 ]
Accepted
196 [ 44 44 50 58 ]
Accepted
197 [ 44 44 50 56 ]
Accepted
198 [ 44 44 50 58 ]
Accepted
199 [ 46 52 52 54 66 68 80 ]
Accepted
200 [ 44 44 50 58 ]
Accepted
201 [ 46 48 52 52 54 64 70 72 ] Accepted
202 [ 46 48 52 52 54 64 70 72 ] Accepted
203 [ 46 48 52 52 54 64 70 72 ] Accepted
204 [ 48 52 52 54 66 70 72 ]
Accepted
205 [ 48 52 52 54 66 70 72 ]
Accepted
206 [ 46 48 52 52 54 79 ]
Accepted
207 [ 50 56 ]
Rejected
208 [ 44 50 56 ]
Accepted
209 [ 44 44 50 58 ]
Accepted
Test Results:
Accepted: 453 out of 500 (0.906)
###################################################################
TA1.test.classify.txt:
Classification of the input sentences to acceptable and non-acceptable according
to the acquired grammar. 1 - acceptable , o - non-acceptable.
MULTI-LEARNERS
Testing precision with multiple learners is done
in the same manner as with a single one: each learner is tested separately. The
recall test, however, is a bit different: each learner is tested, and the
classification results are accumulated in proj_name.test.classify.txt file. Each
recall test adds its results into the file, so that at the end line i of
proj_name.test.classify.txt contains the number of times the learners accepted
sentence i of the test set.
PRINTING
The patterns can be visualized using Matlab, by invoking
the print option. To display the patterns, do the following:
./adios.exe -a print -i TA1.idx
Then run Matlab, set the workspace to the
directory where ADIOS resides, and use the following function:
pattern(123, 'TA1');
where 123 is the ID of the pattern or Equivalence Class,
and TA1 is the ADIOS project name. You should see the pattern displayed in a
tree form. Equivalence classes appear in blue, terminals in black, and patterns
in red.
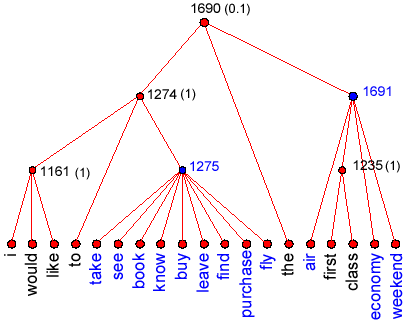
The number in parentheses are the generalization factors.
|






